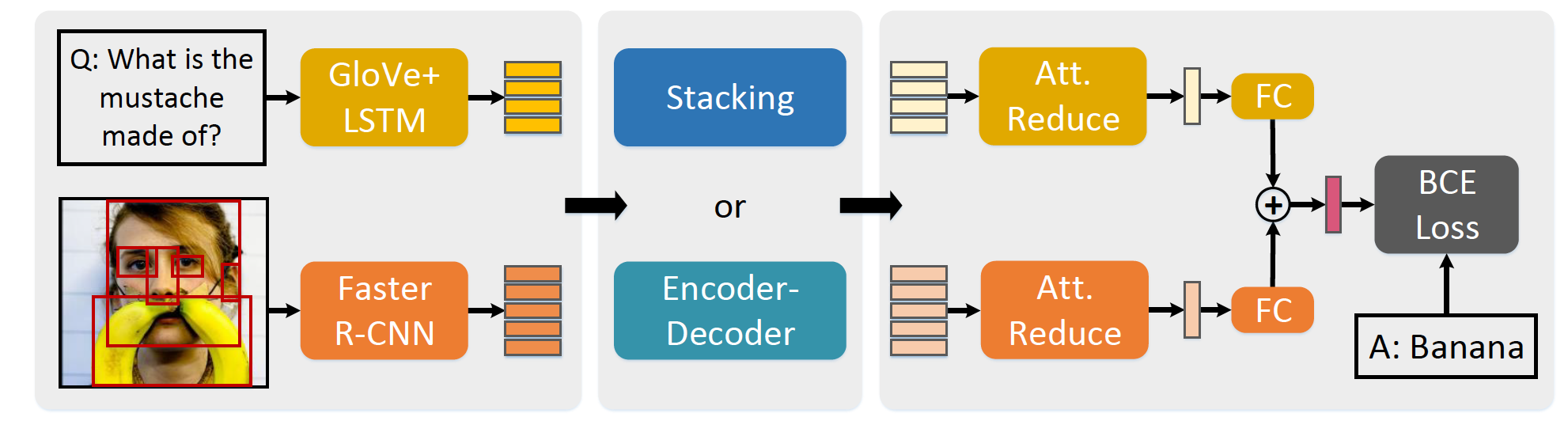
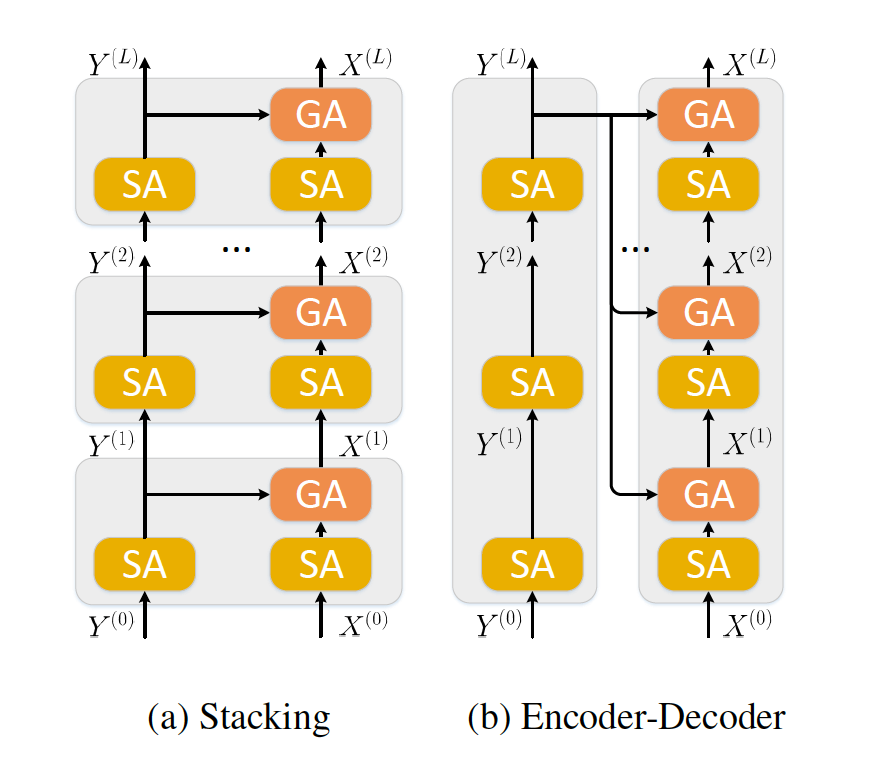
Visual Question Answering
Created by Yuwei SunAll posts
VQA2 Dataset
Visual Question Answering (VQA) v2.0 [1] is a dataset containing open-ended questions about images. VQA2 includes more than 204k images from the MSCOCO dataset, with at least 3 questions per image, 10 ground truth answers per question. The question types covers "yes/no questions", "number counting questions", "other questions about contents of an image".

Language Priors in VQA
The problem of language-prior [2][3][4][5], that a VQA model predicts question-relevant answers independent of image contents. VQA models tend to answer questions based on the high-frequency answers to a certain type of question ignoring image contents. A solution [6] to this problem is to measure the question-image correlation by training on both relevant and irrelevant question-image pairs based on self-supervised learning.
State-Of-The-Art Approaches
Attention
The self-attention [7] module in the Transformer employs the multi-head attention mechanism in which each head maps a query and a set of key-values pairs to an output. The output in a single head is computed as a weighted sum of values according to the attention score computed by a function of the query with the corresponding key. These single-head outputs are then concatenated and again projected, resulting in the final values:
$$\mbox{Multi-head}(Q,K,V)=\mbox{Concat}(\mbox{head}^1,\dots,\mbox{head}^H)W^O,$$ $$\mbox{head}^i=\mbox{Attention}(QW^{Q_i},KW^{K_i},VW^{V_i}),$$ $$\mbox{Attention}(\tilde{Q},\tilde{K},\tilde{V})=\mbox{softmax}(\frac{\tilde{Q}\tilde{K}^T}{\sqrt{d_k}})\tilde{V},$$where $W^Q,W^K,W^V$ and $W^O$ are linear transformations for queries, keys, values and outputs. $\tilde{Q}= QW^{Q_i}$, $\tilde{K} = KW^{K_i}$, and $\tilde{V} = VW^{V_i}$. $d_k$ denotes the dimension of queries and keys in a single head. In self-attention modules, $Q = K = V$.
Stacked Attention Networks [8]

Let The VQA model be represented by the function $h$ which takes an Image ($I$) and a Question ($Q$) as input and generates an answer $A$. We want to estimate the most likely answer $\hat{A}$ from a fixed set of answers.
$\hat{A}=\mbox{argmax}_AP(A|I,Q)$, where the answers $A\in \{A_1, A_2,\dots,A_M\}$ are chosen to be the most frequent $M$ answers from the training set.- Image Channel: This channel provides an embedding for the image by adopting the (normalized) activations $\phi$ from the last hidden layer of a pretrained model such as VGGNet. In particular, VGGNet parameters are frozen to those learned for ImageNet classification and not fine-tuned in the image channel. $\phi = \mbox{CNN}(I)$,$ \phi \in \mathbb{R}^{512\times14\times14}$. $14\times14$ is the number of regions in the image and $512$ is the dimension of the feature vector for each region. Then, $f_i, i \in [0, 195]$ denotes each feature vector corresponding to a $32\times32$ region of the input images. Moreover, a single layer perceptron is applied to transform each feature vector to the same dimension as the question vector. $$v_I=\mbox{tanh}(W_If_I+b_I)$$
- Question Channel: Given the question $q = [q_1,q_2,\dots,q_T]$, where $q_t$ is the one hot vector representation of word at position $t$, we first embed the words to a vector space through an embedding matrix $x_t = W_eq_t$. We feed the embedding vector of words in the question to LSTM. $h_T =\mbox{LSTM}(x_T)$. Then the final hidden layer is taken as the representation vector for the question, i.e., $v_Q = h_T$.
- Stacked attention networks(SAN): Given the image feature matrix $v_I$ and the question feature vector $v_Q$, SAN predicts the answer via multi-step reasoning. In particular, we first feed them through a single layer neural network and then a Softmax function to generate the attention distribution over the regions of the image by the following: $$h_A =\mbox{tanh}(W_{I,A}v_I \oplus(W_{Q,A}v_Q + b_A)),$$ $$p_I =\mbox{Softmax}(W_Ph_A + b_P),$$ where $v_I \in R^{d\times m}, d$ is the image representation dimension and $m$ is the number of image regions, $v_Q \in R^d$ is a $d$ dimensional vector. Suppose $W_{I,A},W_{Q,A} \in R^{k\times d}$ and $W_P \in R^{1\times k}$, then $p_I \in R^m$ is an $m$ dimensional vector. $p_I$ corresponds to the attention probability of each $32\times32$ pixel image region given $v_Q$.
- The weights are put on the visual regions that are more relevant to the question. $$\tilde{v_I}=\sum_i p_iv_i,$$ $$u=\tilde{v_I}+v_Q,$$ In every layer of SAN, we use the combined question and image vector $u^{k-1}$ as the query for the image. Then, update by $u^k = \tilde{v}_I^k+u^{k-1}$. We repeat this $K$ times (1 or 2 times report the best performance in the paper) and then use the final $u^K$ to infer the answer.
- Multi-Layer Perceptron (MLP): The output of the SAN is used as the input of MLP. $$p_ans =\mbox{Softmax}(W_uu^K + b_u)$$
Multi-modal Factorized High-order pooling approach [9]
For multi-modal feature fusion, Multi-modal Factorized High-order pooling approach (MFH) is developed to achieve more effective fusion of multi-modal features by exploiting their correlations sufficiently. Moreover, for answer prediction, the KL (Kullback-Leibler) divergence is used as the loss function to achieve precise characterization of the complex correlations between multiple diverse answers with same or similar meaning.
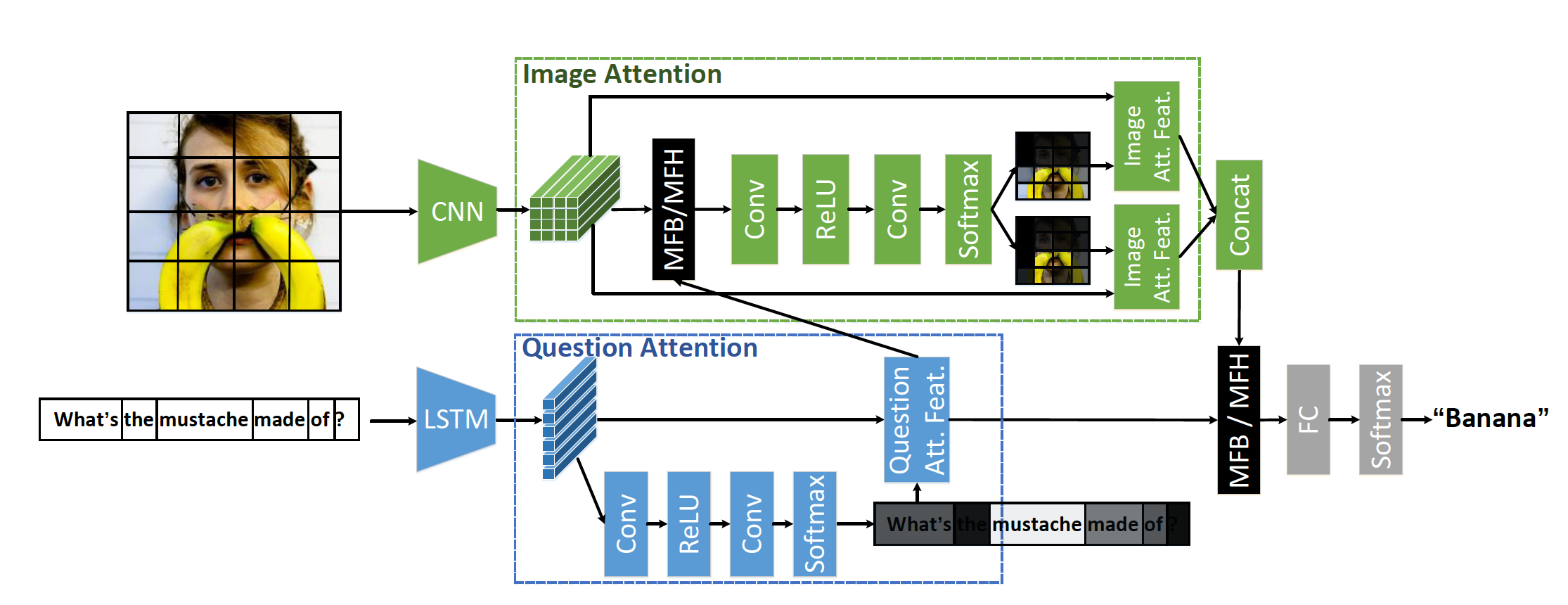
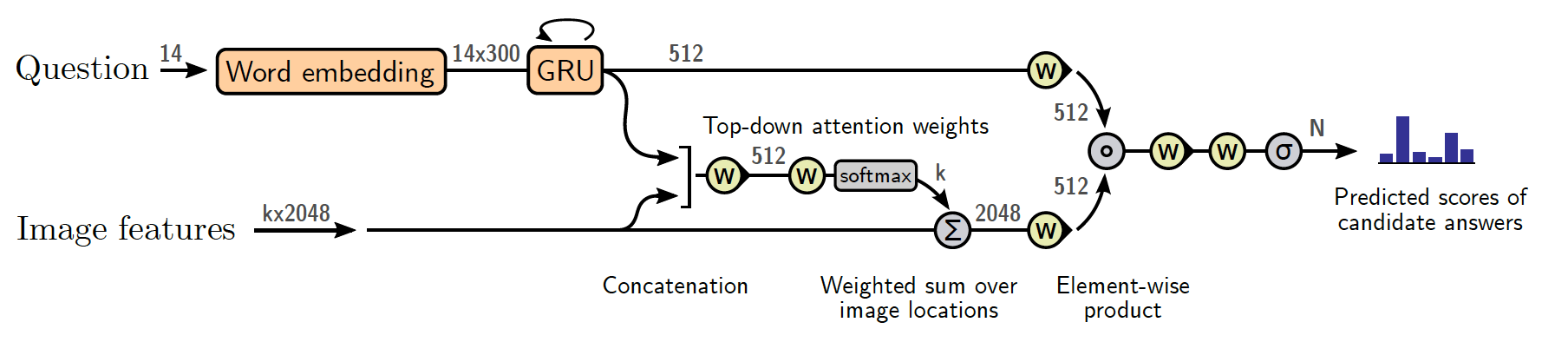
Bottom-up and Topdown Attention mechanism [10]
Bottom-up and Topdown Attention mechanism (BUTD) enables attention to be calculated at the level of objects and other salient image regions. The bottom-up mechanism based on Faster R-CNN proposes image regions, each with an associated feature vector, while the top-down mechanism determines feature weightings.
Bilinear Attention Networks [11]
Bilinear Attention Networks (BAN) finds bilinear attention distributions to utilize given vision-language information seamlessly. BAN considers bilinear interactions among two groups of input channels, while low-rank bilinear pooling extracts the joint representations for each pair of channels.

MultiModal neural architecture search [12]
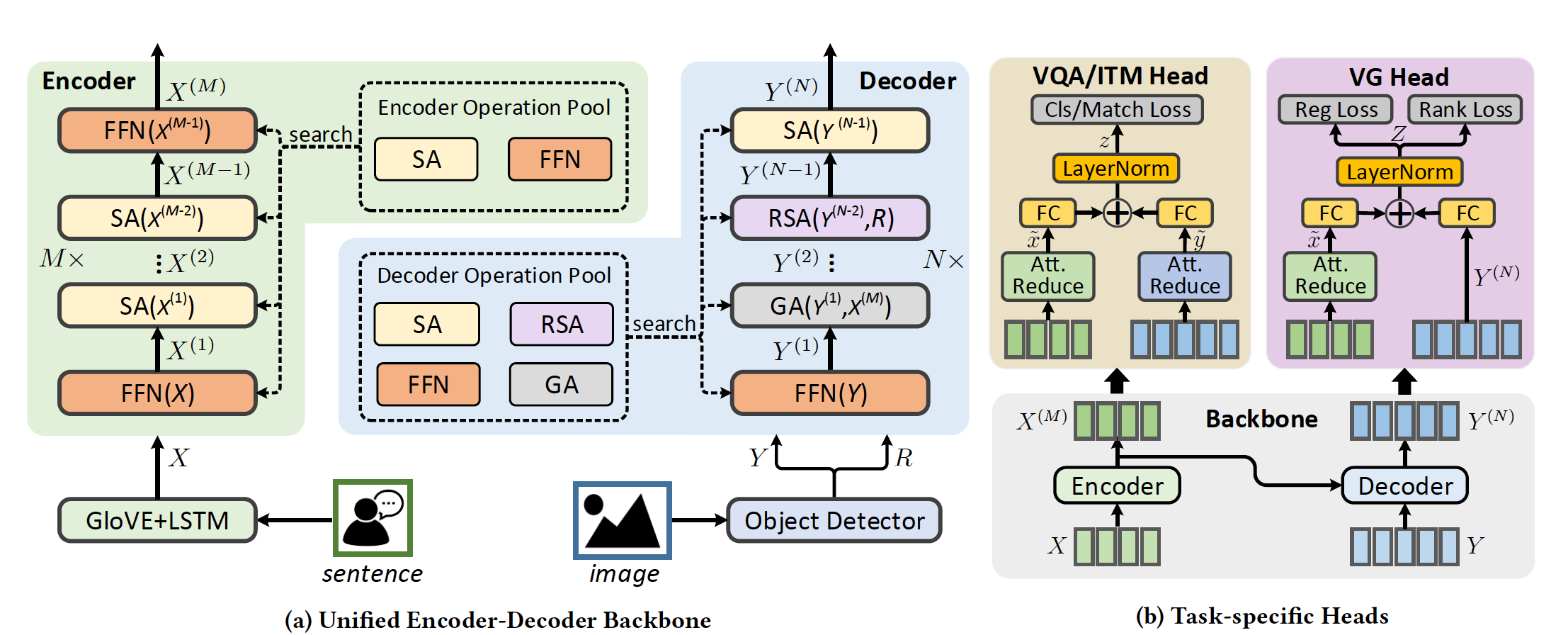
Given multimodal input, multimodal neural architecture search (MMnas) first define a set of primitive operations, and then construct a deep encoder-decoder based unified backbone, where each encoder or decoder block corresponds to an operation searched from a predefined operation pool. On top of the unified backbone, we attach task-specific heads to tackle different multimodal learning tasks. By using a gradient-based NAS algorithm, the optimal architectures for different tasks are learned efficiently.
Modular Co-Attention Network [13]
Modular Co-Attention Network (MCAN) consists of Modular Co-Attention (MCA) layers cascaded in depth. Each MCA layer models the self-attention of questions and images, as well as the guided-attention of images jointly using a modular composition of two basic attention units.